프롤로그
이번 글에서 다루려고 하는 Executor framework는 지금까지 작성해온 스레드 관련된 글에서 예제 코드를 통해 이미 많이 등장했던 내용이다. 전통적인 방법으로 Runnable을 구현하여 Task를 만들고 start()를 호출하여 새로운 스레드를 만드는 방법을 사용하다 보면 자칫 너무 많은 스레드를 만들어 오히려 효율을 떨어뜨리는 문제가 있다. 이런 문제의 해결을 위해 JAVA 1.5에서 처음 이 개념이 등장했다. 적절한 thread 수를 유지시키고 submit 된 작업을 먼저 Queuing 하고 이를 준비된 thread들이 가져다 작업을 하고 결과를 반환하는 방식이다.
Executor framework Overview
다음 그림은 서론에서 설명한 작업 Queue와 Thread pool로 구성된 Executor의 핵심구조이다. Executor에 작업을 등록(submit)하면 Future 라고하는 미래형 티켓을 발급한다. Thread pool 내의 thread중 하나의 thread가 작업을 가져다 수행을 하고 이 티켓에 작업 결과를 연결한다. 문득 요리사가 여러 명 있는 큰 식당의 주방이 떠오른다. 웨이터가 주문을 받고 주문서를 지정된 위치에 등록해두면 요리사들은 순차적으로 이 주문서에 맞는 조리를 시작한다. 조리가 끝나면 이 주문서와 해당 요리를 다시 웨이터가 가져갈 수 있는 위치에 올려놓는다. 웨이터는 다른 일을 하면서 주기적으로 이 위치에 요리를 확인하고 손님에게 서브를 하는 절차를 수행한다. Executor framework은 이와 같은 thread pool을 구성하고 다룰 수 있는 일련의 구조를 제시한다.

[Executor framework 은유]
다음 그림은 이와 관련된 주요 interface와 class들의 class diagram이다.
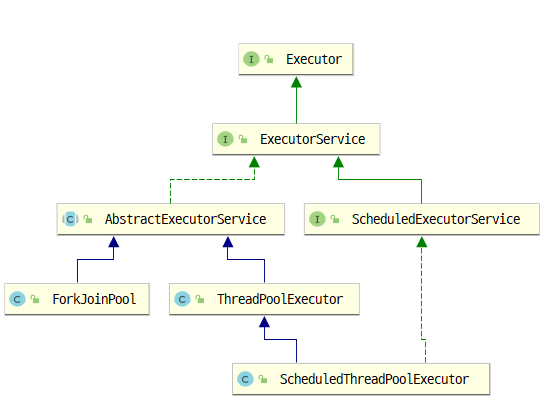
[Executor framework classes]
이 외에도 스레드의 task를 정의하는 interface인 Runnable과 Callable 그리고 적절한 스레드 풀을 생성하게 도와주는 helper class인 Executors class도 많이 사용한다.
ThreadPoolExecutor
상속 구조를 보면 인터페이스 상층에 Executor와 ExecutorService가 정의되어 있다. Executor에는 execute 가 유일한 함수다. 일반적으로 ExecutorService 인터페이스를 이용하여 thread pool을 다룬다. execute 함수는 task가 끝나면 해당 thread 도 파괴되기 때문에 효율이 떨어진다. 그렇기 때문에 특별한 경우가 아니라면 submit 함수를 이용하여 작업 실행을 요청하는 것이 일반적인데 그러기 위해서는 최소한 ExecutorService를 이용해야 한다. 다음 그림은 thread pool 동작 메커니즘을 설명하고 있다. ThreadPoolExecutor를 생성하고 이를 통해서 작업을 submit하면 해당 작업은 Queue에 등록이 Future라고 하는 티켓을 반환한다. 미리 혹은 즉시 생성된 Thread는 해당 작업을 수행하고 Future의 상태를 변경한다. (isDone() 함수로 확인할 수 있다.) 작업을 요청한 thread는 Future의 상태를 계속(주기적으로) 감시하여 완료가 확인이 되면 get() 함수를 통해 결과를 얻는다. 작업에서 예외가 발생한다면 get() 함수를 호출할 때 예외가 catch된다.
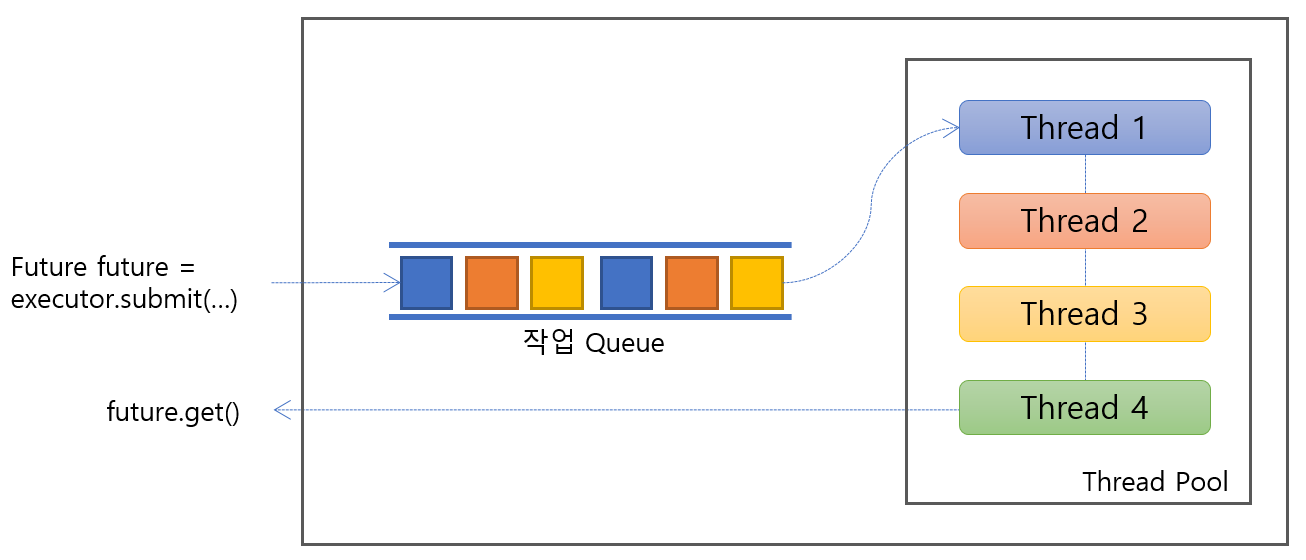
[Executor framework flow]
public int newFixedThreadPoolExamBySubmitAndFuture() {
ExecutorService es = Executors.newFixedThreadPool(5);
Future<Integer> future = es.submit(new SomeCallableTask());
es.shutdown();
while (!future.isDone()) {
try {
// 이 스레드에서 다른 작업을 수행하는 것을 대신해 아래와 같이 sleep 을 둔다.
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
int result = -1;
try {
result = future.get();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
return result;
}
/**
* Callable<T> 방식의 thread Task 정의
*
*/
static class SomeCallableTask implements Callable<Integer> {
@Override
public Integer call() {
System.out.println("Current thread name: " + Thread.currentThread().getName());
return 0;
}
}
[미래의 결과 값 Future]
다음은 ThreadPoolExecutor의 생성자 프로토타입 이다. 이를 통해 thread pool을 좀더 상세히 알아보도록 하자. corePoolSize 나 maximumPoolSize 는 thread pool 에 관련된 크기이다. 작업 Queue의 사이즈와는 무관함을 강조한다. 그러니 개발자는 이 사이즈와 무관하게 필요한 만큼 executor에게 작업을 요청해도 된다. 물론 Queue가 허용하는 범위 내에서 말이다.
/**
* Creates a new {@code ThreadPoolExecutor} with the given initial
* parameters.
*
* @param corePoolSize the number of threads to keep in the pool, even
* if they are idle, unless {@code allowCoreThreadTimeOut} is set
* @param maximumPoolSize the maximum number of threads to allow in the
* pool
* @param keepAliveTime when the number of threads is greater than
* the core, this is the maximum time that excess idle threads
* will wait for new tasks before terminating.
* @param unit the time unit for the {@code keepAliveTime} argument
* @param workQueue the queue to use for holding tasks before they are
* executed. This queue will hold only the {@code Runnable}
* tasks submitted by the {@code execute} method.
* @param threadFactory the factory to use when the executor
* creates a new thread
* @param handler the handler to use when execution is blocked
* because the thread bounds and queue capacities are reached
* @throws IllegalArgumentException if one of the following holds:<br>
* {@code corePoolSize < 0}<br>
* {@code keepAliveTime < 0}<br>
* {@code maximumPoolSize <= 0}<br>
* {@code maximumPoolSize < corePoolSize}
* @throws NullPointerException if {@code workQueue}
* or {@code threadFactory} or {@code handler} is null
*/
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
RejectedExecutionHandler handler)
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory)
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue)
| 파라미터 | 설명 |
|---|---|
| corePoolSize | 유휴상태 즉 작업 Queue에 처리 대상이 하나도 없어도 유지해야 하는 최소 스레드의 수, 단 allowCoreThreadTimeOut 설정이 true로 설정되지 않은 경우, 0 이상의 정수 |
| maximumPoolSize | thread pool 내에 허용되는 최대 스레드 수, 1 이상의 정수, corePoolSize 보다 작을수 없다. |
| keepAliveTime | 스레드 수가 corePoolSize 보다 크면 초과 유휴 스레드가 종료되기 전에 새 작업을 기다리는 최대 시간 (thread pool은 할일이 없다면 corePoolSize를 유지하려고 한다.) , 0 이상의 정수 |
| unit | keepAliveTime 인자에 적용되는 시간 단위이다. |
| workQueue | 작업을 실행시키기 전에 대기시키는 Queue |
| threadFactory | executor가 새로운 thread를 만들때 사용하는 factory |
| handler | thread의 한계 수치나 Queue의 용량을 초과 할 때 사용할 헨들러 |
execute와 submit method에 대한 고찰
두 메소드의 공통점은 executor에게 작업을 요청한다는 것이다. execute는 요청 작업의 인자로 Runnable만 허용을 하고 submit은 Runnable과 Callable interface를 모두 허용한다. 이는 submit 은 작업의 결과를 받을 수 있음의 의미한다. 그래서인지 예외가 발생할 경우 execute의 경우 반환의 통로가 없기 때문에 JVM에 예외가 전파되고 해당 thread는 파괴된다. submit은 get을 하여 처리 결과를 확인하기 전까지는 예외 발생을 확인할 방법이 없다. 당연한 이야기지만 submit 처리 중 오류가 발생해도 thread는 process에 남아있으며 재활용의 대상이 된다.
public class HowToUseExecutorService {
private static String NEW_LINE = System.lineSeparator();
private static Map<String, String> lastExceptionThreadName = new ConcurrentHashMap<>();
static {
lastExceptionThreadName.put("BySubmit-Thread_", "");
lastExceptionThreadName.put("ByExecute-Thread_", "");
lastExceptionThreadName.put("BySubmit-Thread_2", "");
lastExceptionThreadName.put("ByExecute-Thread_2", "");
GlobalUnhandledExceptionHandler globalUnhandledExceptionHandler
= new GlobalUnhandledExceptionHandler(
(t, e) -> {
String threadName = t.getName();
if ( threadName.contains("BySubmit-Thread_") ) {
lastExceptionThreadName.replace("BySubmit-Thread_", threadName);
} else if (threadName.contains("ByExecute-Thread_")) {
lastExceptionThreadName.replace("ByExecute-Thread_", threadName);
} else if ( threadName.contains("BySubmit-Thread2_") ) {
lastExceptionThreadName.replace("BySubmit-Thread_", threadName);
} else if (threadName.contains("ByExecute-Thread2_")) {
lastExceptionThreadName.replace("ByExecute-Thread_", threadName);
}
String errMsg = "### caught exception in static constructor. ###" + NEW_LINE;
errMsg += "Occur exception... thread name: " + t.getName() + NEW_LINE;
System.out.println(errMsg);
});
Thread.setDefaultUncaughtExceptionHandler(globalUnhandledExceptionHandler);
}
/**
* Runnable 방식의 thread Task 정의, 실행하면서 Runtime Exception 이 throw 된다.
*
*/
static class ThrowsExceptionRunnableTask implements Runnable {
@Override
public void run() {
System.out.println("Current thread name: " + Thread.currentThread().getName());
Integer intResult = Integer.parseInt("삼"); // occurs exception ...
// 실행 되지 않음
System.out.println("This code exists after the code causing the error.");
}
}
/**
* submit 의 실행 대상이 Exception 을 throw 하면 해당 작업은 거기서 종료가 되고 thread 는 재활
* 용 된다. ByExecute-Thread_5' 라는 이름의 thread 까지 생성된다. Exception 은 전파되지 않는다.
*
*/
public String throwsExceptionRunnableTaskUsingSubmit() {
lastExceptionThreadName.replace("BySubmit-Thread_", "");
ExecutorService es = Executors.newFixedThreadPool(5, new ThreadFactory() {
private int counter = 1;
@Override
public Thread newThread(Runnable runnable) {
Thread t = new Thread(runnable, "BySubmit-Thread_" + counter);
counter++;
return t;
}
});
for(int i = 0; i < 10 ; i++) {
Future<?> future = es.submit(new ThrowsExceptionRunnableTask());
}
es.shutdown();
try {
es.awaitTermination(30, TimeUnit.SECONDS);
} catch (InterruptedException e) {
e.printStackTrace();
}
return lastExceptionThreadName.get("BySubmit-Thread_");
}
/**
* execute 의 실행 대상이 Exception 을 throw 하면 해당 thread 가 깨진다.
* 해서 'ByExecute-Thread_10' 라는 이름의 thread 까지 생성된다.
* 해당 Exception 은 전파된다.
*/
public String throwsExceptionRunnableTaskUsingExecute() {
lastExceptionThreadName.replace("ByExecute-Thread_", "");
ExecutorService es = Executors.newFixedThreadPool(5, new ThreadFactory() {
private int counter = 1;
@Override
public Thread newThread(Runnable runnable) {
Thread t = new Thread(runnable, "ByExecute-Thread_" + counter);
counter++;
return t;
}
});
for(int i = 0; i < 10 ; i++) {
es.execute(new ThrowsExceptionRunnableTask());
}
es.shutdown();
try {
es.awaitTermination(30, TimeUnit.SECONDS);
} catch (InterruptedException e) {
e.printStackTrace();
}
return lastExceptionThreadName.get("ByExecute-Thread_");
}
}
/**
* submit 은 예외를 먹는다. 결과를 돌려 받을 수 있는 방법을 제공한다. 스레드를 재사용한다.
*
* 테스트는 submit 가 예외를 먹어서 전역 예외처리기에 아무런 Feedback 도 하지 않아 함수의
* 반환 값인 예외를 던진 마지막 Thread 이름이 빈 값인지를 단정한다.
*/
@Test
public void executorSubmit() {
HowToUseExecutorService testTarget = new HowToUseExecutorService();
String last = testTarget.throwsExceptionRunnableTaskUsingSubmit();
Assert.assertEquals("", last);
}
/**
* 예외가 발생하면 해당 Thread 는 깨진다.
*
* 테스트는 execute 가 예외를 JVM 에 전파 시키기 때문에 Feedback 이 전달되어 함수의 반환
* 값인 예외를 던진 마지막 Thread 이름이 빈 값이 아닌지 단정한다.
*/
@Test
public void executorExecute() {
HowToUseExecutorService testTarget = new HowToUseExecutorService();
String last = testTarget.throwsExceptionRunnableTaskUsingExecute();
Assert.assertNotEquals("", last);
}
[submit과 execute의 오류처리 차이]
execute 로 thread task를 실행하다 예외가 발생하면 해당 thread는 파괴된다고 이미 위에서 언급했다. 그런 이유로 execute에 의해 실행된 ThrowsExceptionRunnableTask에서 출력한 스레드 이름을 유심히 보면 오류 발생으로 이해 thread가 파괴되어 10개 까지 생성되었음을 확인 할 수 있다.
Current thread name: ByExecute-Thread_1
Current thread name: ByExecute-Thread_2
…<중략>..
Current thread name: ByExecute-Thread_6
Current thread name: ByExecute-Thread_10
ForkJoinPool
executor framework의 구현 class들 중에 ForkJoinPool이라는 class가 있다. 이는 큰 업무를 작은 단위로 나누고(fork) 정해진수의 thread가 이를 처리한 후 결과를 취합하는 방법을 제시한다. 이는 분할정복 알고리즘에 기초한다.
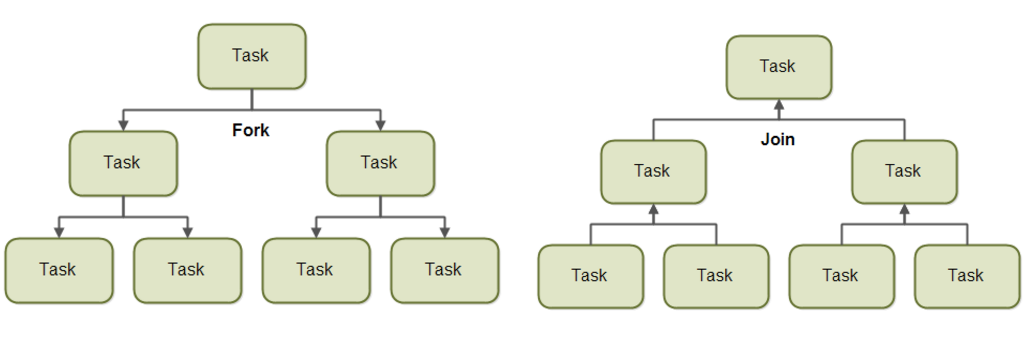
[분할과 취합]
executor framework의 구현 class들 중에 ForkJoinPool이라는 class가 있다. 이는 큰 업무를 작은 단위로 나누고(fork) 정해진수의 thread가 이를 처리한 후 결과를 취합하는 방법을 제시한다. 이는 분할정복 알고리즘에 기초한다.
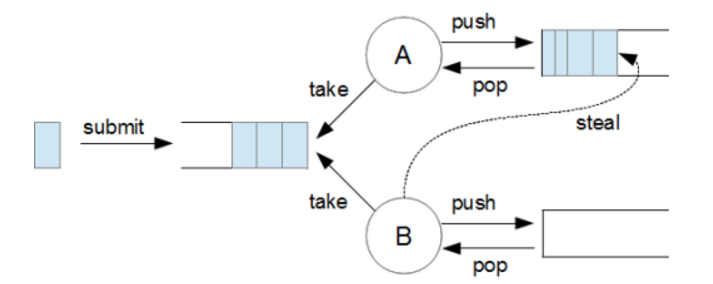
[각 스레드의 deque 그리고 steal 작용]
그러나 뭐든 만병통치약은 없다. 이 방법을 사용하려면 작업을 분할 하는 명확한 기준이 필요하다. 통상 들어 자료구조가 Hierarchy와 같이 하위 노드로 작업을 분할 할 수 있는 명확한 기준이 있는 경우에 유용하다. 또한 자칫 Queue와 Deque를 오가는 오버헤드 때문에 오히려 시스템을 더 느릴수 있다는 말이다. 다음코드는 ForkJoinPool을 이용하여 특정 폴더 하위에 존재하는 모든 .log 파일의 경로 목록을 구하는 예제이다.
import java.io.File;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.RecursiveTask;
public class FolderProcessor extends RecursiveTask<List<String>> {
private static final long serialVersionUID = 1L;
private final String path;
private final String extension;
public FolderProcessor(String path, String extension) {
this.path = path;
this.extension = extension;
}
@Override
protected List<String> compute() {
List<String> list = new ArrayList<String>();
List<FolderProcessor> tasks = new ArrayList<FolderProcessor>();
File file = new File(path);
File content[] = file.listFiles();
if (content != null) {
for (File value : content) {
if (value.isDirectory()) { // 파일 객체가 디렉터리인 경우 작업을 분할 한다.
FolderProcessor task = new FolderProcessor(value.getAbsolutePath(), extension);
task.fork();
tasks.add(task);
}
else {
if (checkFile(value.getName())) {
list.add(value.getAbsolutePath());
}
}
}
}
addResultsFromTasks(list, tasks);
return list;
}
private void addResultsFromTasks(List<String> list, List<FolderProcessor> tasks) {
for (FolderProcessor item : tasks) {
list.addAll(item.join());
}
}
private boolean checkFile(String name) {
return name.endsWith(extension);
}
}
[폴더를 탐색하여 특정 확장자를 갖은 파일의 목록을 구하는 작업 class]
@Test
public void findLogFilesByForkJoinPool() {
ForkJoinPool pool = new ForkJoinPool();
FolderProcessor system = new FolderProcessor(USER_HOME_DIR, "log");
pool.submit(system);
do {
// Thread pool 의 상태를 모니터링 함
System.out.print("****************************************************** \n");
System.out.printf("병렬처리 (최대)수 : %d\n", pool.getParallelism());
System.out.printf("활성화된 스레드 수: %d\n", pool.getActiveThreadCount());
System.out.printf("큐내의 작업 수: %d\n", pool.getQueuedTaskCount());
System.out.printf("Pool 전체에서 빼앗긴 작업 수: %d\n", pool.getStealCount());
System.out.print("****************************************************** \n");
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
} while (!system.isDone());
pool.shutdown();
List<String> results;
results = system.join();
System.out.printf("Total target extension Files: %d \n", results.size());
for(String logFile : results) {
System.out.printf("%s\n", logFile);
}
}
[FolderProcessor 작업 class를 사용하는 ForkJoinPool Test code]
아래는 테스트 진행중 pool의 상태를 출력한 결과이다. 병렬처리 스레드 수는 기본값으로 시스템의 코어 수를 갖게 되어 있다. 활성화되 스레드 수 역시 이 값을 넘을수 없다. 큐내의 작업수(getQueuedTaskCount)는 등록된 총 작업수를 의미한다. getStealCount은 pool 전체에서 빼앗긴 작업의 수를 말한다.
******************
병렬처리 (최대)수 : 4
활성화된 스레드 수: 4
큐내의 작업 수: 14
Pool 전체에서 빼앗긴 작업 수: 1
******************
******************
병렬처리 (최대)수 : 4
활성화된 스레드 수: 4
큐내의 작업 수: 422
Pool 전체에서 빼앗긴 작업 수: 30
******************
******************
병렬처리 (최대)수 : 4
활성화된 스레드 수: 4
큐내의 작업 수: 261
Pool 전체에서 빼앗긴 작업 수: 44
******************
******************
병렬처리 (최대)수 : 4
활성화된 스레드 수: 4
큐내의 작업 수: 263
Pool 전체에서 빼앗긴 작업 수: 45
******************
******************
병렬처리 (최대)수 : 4
활성화된 스레드 수: 23
큐내의 작업 수: 669
Pool 전체에서 빼앗긴 작업 수: 435
******************
******************
병렬처리 (최대)수 : 4
활성화된 스레드 수: 1
큐내의 작업 수: 0
Pool 전체에서 빼앗긴 작업 수: 1120
******************
특정 폴더를 기준으로 검색을 시키면 필자의 PC의 경우 단일 thread, 재귀호출 조건으로 호출한 결과와 비교하면 분명 빠르다. 그러나 fixed thread pool 보다 느린 경우도 있다. 빠른 경우도 있다는 뜻이다. 대체적으로 검색 대상 폴더가 상위 폴더 즉 검색대상이 많은 경우에 약간 우수한 성능을 보이는 것이 일반적 이였다.
애필로그
스레드를 만들고 관리하는 관점에서 executor framework 즉 thread pool은 많은 편리함과 이점을 가져다준다. 그러나 모든 문명의 이기가 그렇듯이 그 특성을 잘 알고 사용하는 것이 좋다. 이번 편에서 다루지 못한 ScheduledExecutorService, 예외처리를 위한 ThreadPoolExecutor의 확장에 대한 글을 예고한다.
참고자료
쓰레드풀 과 ForkJoinPool
About STL : C++ STL 프로그래밍(5)-덱(deque) : (1)
The fork/join framework in Java 7
